Introduction: Hash functions in Cryptography

Cryptographic Hash Functions (CHF) are fundamental to securing the digital world. From protecting passwords to enabling blockchain and zero-knowledge (ZK) systems, CHFs play a crucial role in ensuring the integrity, security, and privacy of data. This blog is the first in a series where we’ll explore the world of cryptographic hash functions, starting with an introduction to their core properties, the mathematical foundation behind them, how they differ from regular hash functions, and why they are critical in today’s cryptographic landscape.
What Is a Cryptographic Hash Function?
A cryptographic hash function is a mathematical algorithm that takes an input of any size and transforms it into a fixed-size string of characters, usually a hexadecimal number. This result is called the hash or digest. The hash outputs appear random, i.e., if even a single bit of the input changes, the hash is expected to change dramatically, but for the same input, the hash function will always generate the same hash.
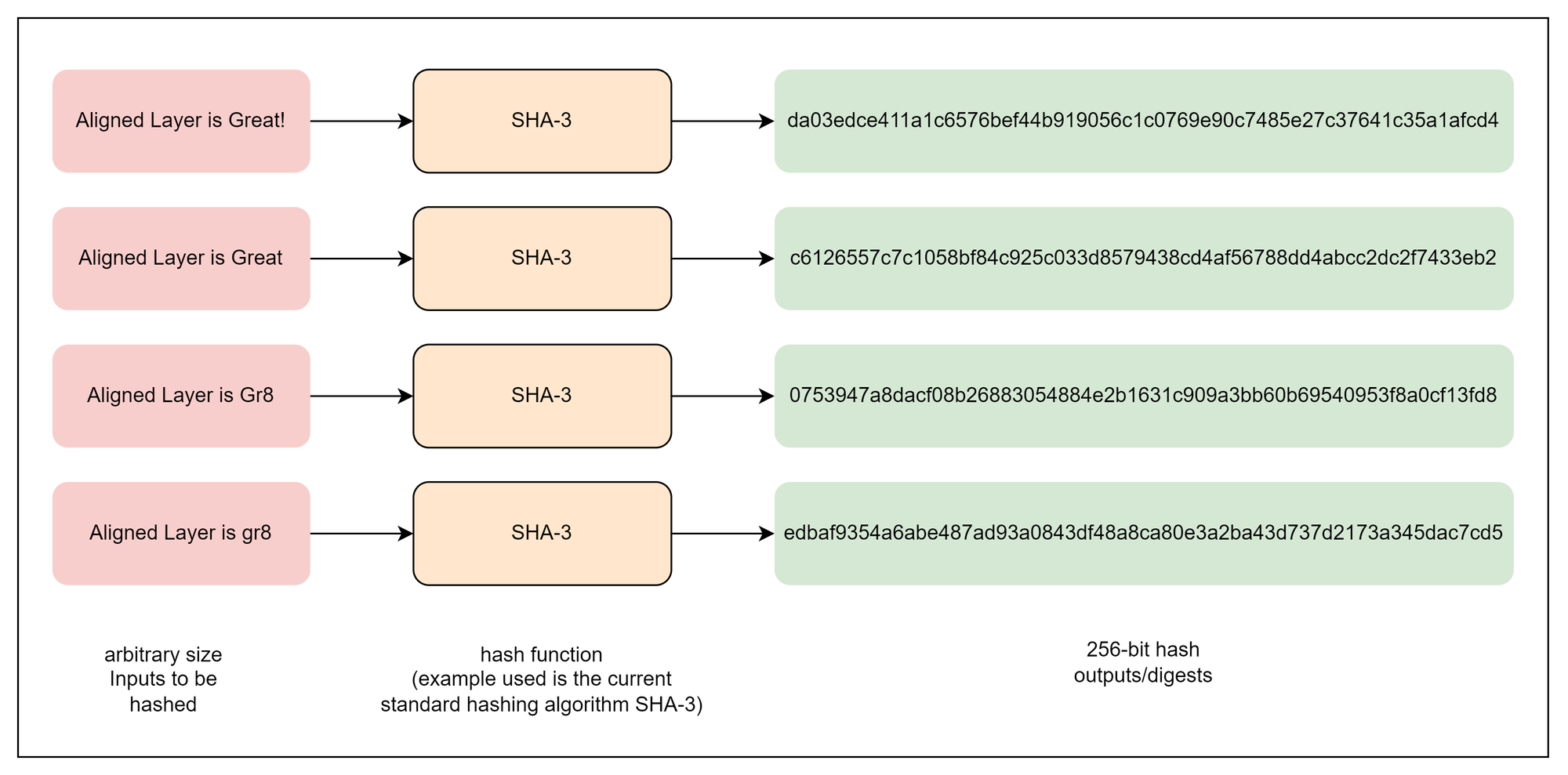
Cryptographic hash functions are designed to be computationally efficient while providing strong security properties. They differ from regular hash functions used in simpler tasks, such as storing data in hash tables, because of their additional security features, which protect against attacks and ensure robustness.
For analogy, think of a cryptographic digest as a digital fingerprint for any piece of information. Just as no two people are likely to share the same fingerprint, no two pieces of data should share the same hash, even if they look similar. This "fingerprint" ensures security in many systems, such as verifying transactions on a blockchain or securing password storage.
Key Properties of Cryptographic Hash Functions
To be considered secure and practical for cryptographic use, a hash function must exhibit three basic security properties:
1. Preimage Resistance
Definition: Given a hash $h$, it should be computationally infeasible to find an input $x$ such that $H(x) = h$. In simpler terms, if you only know the hash, you shouldn’t be able to reverse-engineer the original input.
Analogy: Think of a fingerprint (the hash). Preimage resistance means that even if someone gets a copy of this fingerprint, they can’t figure out whose fingerprint it is (the original input). It's like seeing a fingerprint but having no way to reverse-engineer the identity of the person it belongs to.
2. Second Preimage Resistance
Definition: Given an input $x_1$, it should be computationally infeasible to find another input $x_2$ such that $H(x_1) = H(x_2)$. This prevents an attacker from finding a different input that produces the same hash.
Analogy: Given one person’s fingerprint, second preimage resistance means that it’s nearly impossible to find a different person with an identical fingerprint. Even though the world is full of people, no one can create another fingerprint that exactly matches the one you already have.
3. Collision Resistance
Definition: It should be computationally infeasible to find two distinct inputs $x_1$ and $x_2$ such that $H(x_1) = H(x_2)$. In other words, no two different inputs should produce the same hash.
Analogy: Collision resistance guarantees that no two people can have the exact same fingerprint. Even though millions of people exist, everyone’s fingerprint is unique. Similarly, cryptographic hash functions are designed so that no two distinct inputs will ever produce the same hash value.
These security properties make CHFs suitable for cryptographic applications such as digital signatures, password storage, and blockchain consensus algorithms.
Understanding the Birthday Paradox
The Birthday Paradox is a striking illustration of how probabilities work in unexpected ways. In a group of just 23 people, the chance that two people share the same birthday is over 50%. This seems odd because there are 365 possible birthdays, but the probability isn’t based on comparing each person to 365 days—it’s about comparing each person’s birthday with every other person’s. For 23 people, you’re making 253 comparisons (since each person is compared to every other person, we have 23+22+21+…+1 = 253 comparisons), and that quadratic growth in comparisons means the chance of a shared birthday increases rapidly.

Applying the Birthday Paradox to CHFs
The Birthday Paradox provides valuable insight into how collisions can occur in hash functions. For example, a hash function that produces a 128-bit output has $2^{128}$ possible hash values. Intuitively, you might think that finding two inputs that produce the same hash (a collision) should require testing $2^{128}$ different inputs. However, the Birthday Paradox tells us that an attacker only needs to test about $2^{64}$ inputs to find a collision.
This happens because, much like comparing birthdays at a party, the number of comparisons between hashed values increases exponentially as more inputs are hashed. Therefore, collisions can occur more quickly than expected. By understanding this paradox, we can better appreciate why cryptographic hash functions need to have sufficient output lengths and robust design to minimise collision risks and maintain security.
In summary, the Birthday Paradox is not just a theoretical curiosity but a practical tool for understanding the behaviour of hash functions and their susceptibility to collisions. By applying this concept, we can ensure that cryptographic systems are designed to withstand the probabilistic challenges posed by real-world attacks.
Differences Between Regular and Cryptographic Hash Functions
It’s essential to distinguish cryptographic hash functions from regular hash functions. Regular hash functions are used for tasks like data indexing (e.g., hash tables), where speed is a priority over security. These functions are designed to hash data quickly, but they don’t guarantee the same level of protection against attacks.
In contrast, cryptographic hash functions offer strong security properties, such as collision resistance, preimage resistance or one-wayness, and second preimage resistance, making them suitable for critical applications like securing passwords, creating digital signatures, and ensuring data integrity or tamper protection.
Analogy: Think of regular hash functions like grouping books by their first letter. Two books, "The Adventure of Sherlock Holmes" and "The Adventures of Sherlock Holmes," with similar titles might end up in the same group. Cryptographic hash functions, however, are like assigning each book a unique ISBN. Even if two books are nearly identical, their ISBNs (hashes) will be entirely different, ensuring that each one is uniquely identified.
Random Oracle Model vs. Basic Cryptographic Properties
In many cryptographic applications, hash functions are modelled as random oracles. This is a theoretical concept where the hash function is treated as an ideal black box that provides a random output for each input. The random oracle model allows cryptographers to analyse the security of systems under the assumption that the hash function behaves randomly.
Analogy: Imagine you have access to a magic machine. Every time you put in a unique item (input), the magic machine spits out a completely random and unique prize (output). Importantly, the magic machine will always give you the exact same prize if you put the same item in twice, but no one (not even you) can guess in advance what the prize will be when giving a new item. The machine's responses seem entirely random, but they are consistent. This is like a Random Oracle in cryptography—a theoretical ideal that provides a random yet consistent output for any input.
In contrast, regular cryptographic hash functions, while secure, are not truly random like the magic box. Instead, they are more like a well-designed puzzle machine that produces highly complex, unique, and deterministic outputs for each input. Although you can’t reverse-engineer the puzzle (preimage resistance), and two different inputs won’t yield the same puzzle (collision resistance), the function follows an algorithm. It’s predictable in the sense that the output is not random; it follows a fixed process, just extremely difficult to reverse.
To summarise:
- Random Oracle is like a magic vending machine: unpredictable, random, but always consistent for a given input.
- Real hash functions are more like a complex puzzle machine: not truly random, but secure and unpredictable in practice, thanks to their cryptographic properties like preimage and collision resistance.
This distinction is important because while real hash functions strive to mimic a random oracle’s unpredictability, they are deterministic algorithms bound by their cryptographic properties.
While no real-world hash function can achieve the ideal properties of a random oracle, indifferentiable cryptographic hash functions (a topic to be covered in the upcoming blogs) come close enough to simulating this behaviour, which is especially useful in protocols like zero-knowledge proofs (ZK-proofs) and other applications that model hash functions as random oracles.
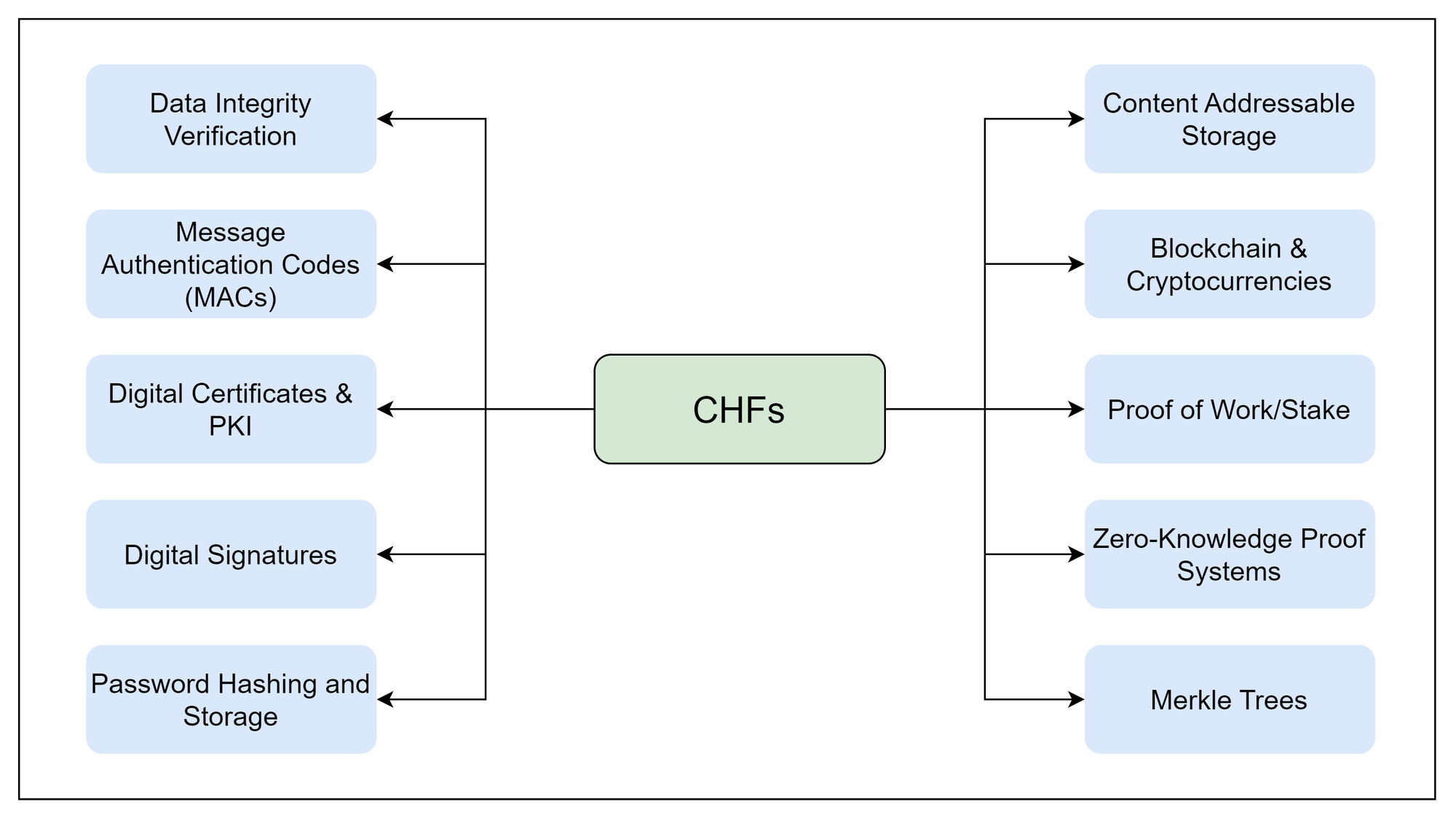
Applications of Cryptographic Hash Functions
Cryptographic hash functions play a vital role in a variety of applications:
- Digital Signatures: Cryptographic hash functions are used to create a unique digest of the data being signed. The digital signature then uses this digest, ensuring that any alteration to the data would invalidate the signature.
- Password Storage: Hash functions are used to store passwords securely. When a user logs in, a secure system should hash the entered password and compares it to the stored hash, ensuring the original password is never directly stored.
- Data Integrity Verification: Hash functions ensure that data has not been altered. By hashing both the original and received data, you can compare the two hashes to verify their integrity.
Conclusion
In this introductory blog, we’ve explored the fundamental properties of cryptographic hash functions and their crucial role in securing digital systems. From understanding the surprising probability principles of the Birthday Paradox to the differences between regular and cryptographic hash functions. Additionally, we've touched upon the increasingly critical role of hash functions as random oracles in modern cryptographic applications, such as in verifying transactions and ensuring the integrity of ZK-proof systems.
As we continue through this blog series, we will dive deeper into the different design strategies for hash functions, their modes of operation, and how they are claimed secure and indifferentiable from a random oracle. Stay tuned for the next blog in the series, where we explore how to construct and operate hash functions efficiently through various modes.
What's Next?
In the next blog, Design Strategies: How to Construct A Hashing Mode?, we will explore different hashing strategies, such as tree hashing and iterated hashing, and look at some hashing modes, such as Merkle-Damgård and Sponge functions. We will then discuss their security and efficiency properties and explain why certain modes are better suited for specific applications.
Stay tuned: 🐦 Twitter | 🗨️ Telegram | 👾 Discord | 🌐 Website | 📝 Manifesto


