Hackathon Spotlight Vol. 03: Building Trust in Vector Spaces with Verifiable Nearest-Neighbor Search

How can we be sure that a vector database returns the truly best match? This hackathon project by Erhan uses verifiable computation and zero-knowledge proofs to mathematically guarantee the accuracy of nearest neighbor searches, enabling more transparent and trustworthy AI-powered applications.
The Semantic Revolution
Semantic generally refers to the meaning or interpretation behind words, phrases, symbols, or any data. In computing, especially in areas like natural language processing, “semantic” focuses on understanding the contextual and conceptual meaning behind text. This helps machines (and people) better understand and respond to language in a more human-like, meaningful way.
At the core of modern AI lies semantic understanding, the ability to go beyond words or raw data to uncover real, contextual meaning. This is where vector embeddings come into play, translating text, images, and even audio into dense, high-dimensional representations that capture their deeper significance. With the right infrastructure, specifically vector databases, we can efficiently store, search, and verify these embeddings at scale.
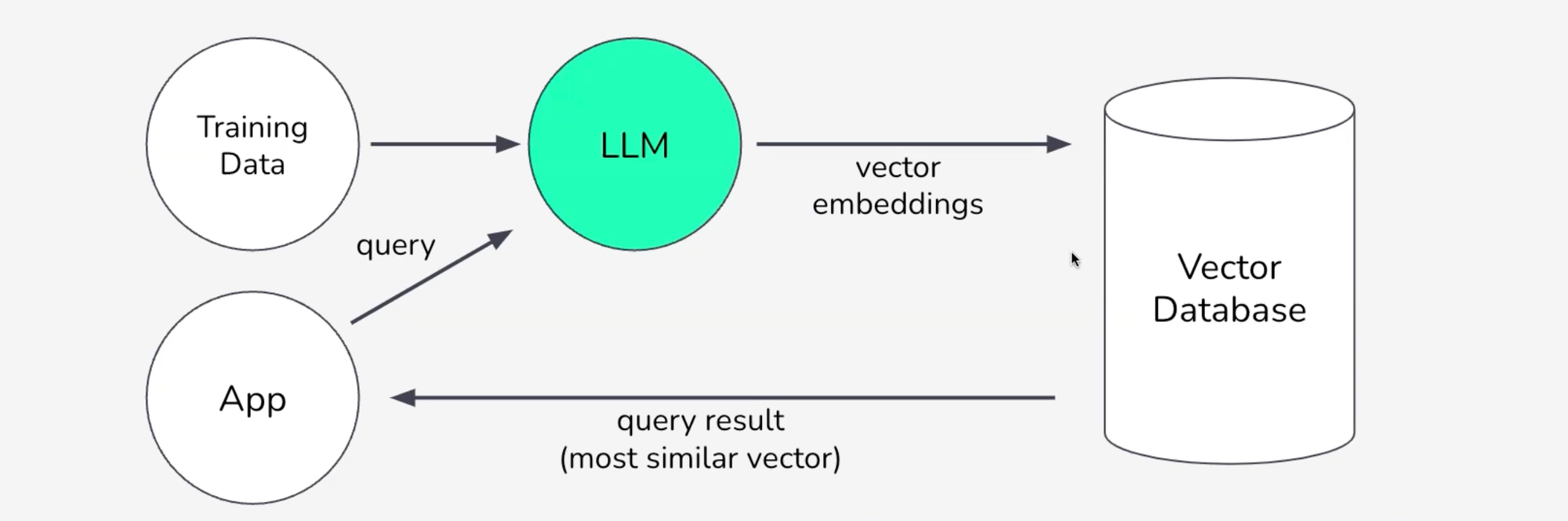
Vector Databases: Storing High-Dimensional Vectors for Fast Similarity Search
Vector databases focus on storing and retrieving vector embeddings, which are high-dimensional representations of data (e.g. from machine learning models). Rather than matching exact words or fields, these databases use vector similarity search (like Euclidean or cosine distance) to find items that are closest in meaning or features.
This approach powers applications like recommendation systems, semantic search, and anomaly detection by quickly identifying the items most relevant to a user’s query or context, all in real-time, at scale.
Vector Embeddings: The Foundation of Semantic Understanding
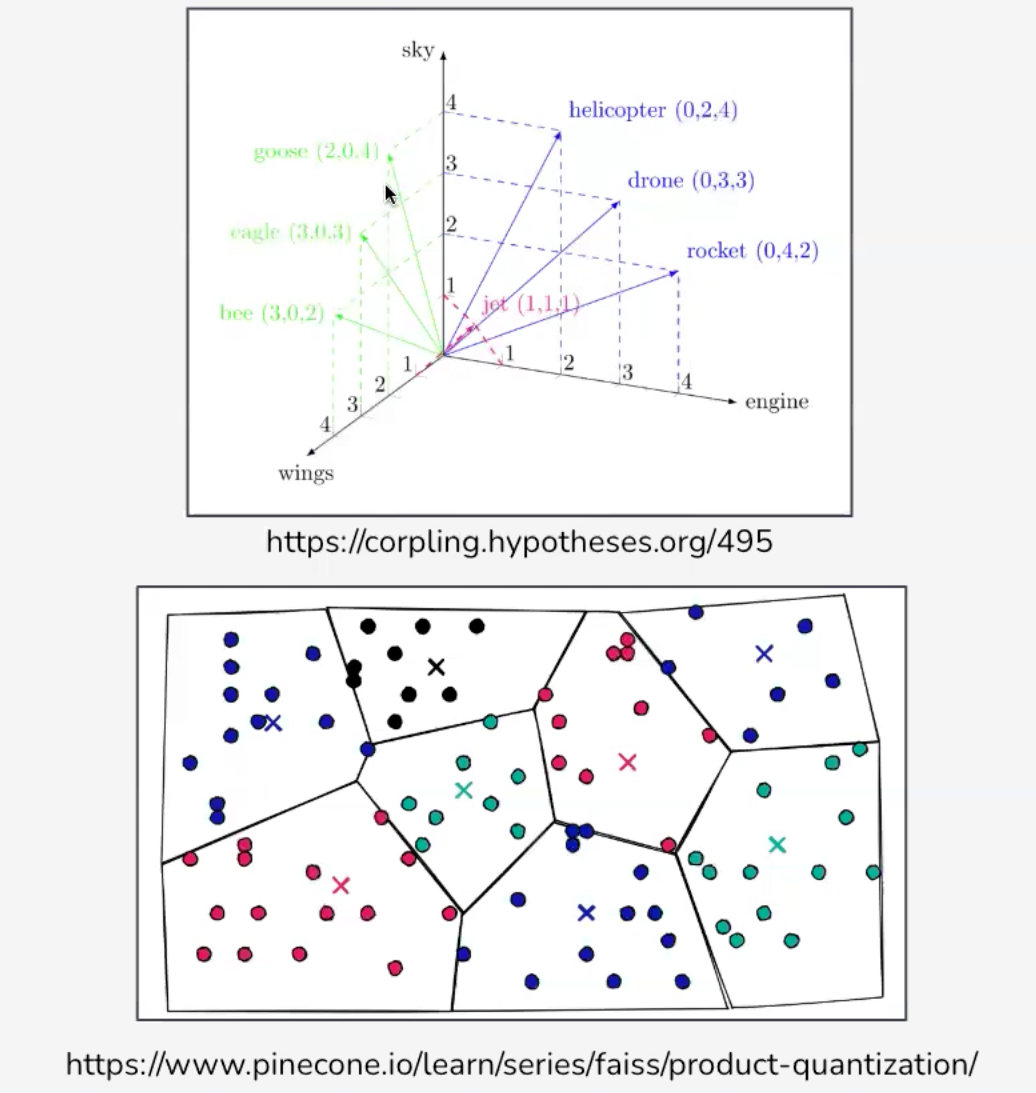
Vector embeddings are numerical representations of data, text, images, audio, or any input that capture the key features and context in a way that similar items cluster together in the embedding space. By creating these dense, high-dimensional vectors (using neural networks or other ML techniques), we can move beyond simple keyword matching to uncover deeper, more meaningful relationships among data.
Whether it’s semantic search, recommendations, clustering, or cross-modal tasks, embeddings power many of today’s most advanced AI applications. And to handle the scale and speed required for embedding-based queries, specialized vector databases like Pinecone, provide the infrastructure needed to store, index, and query these representations.
Building Trust in Vector Spaces
In many AI-driven applications, whether it’s a recommendation system, a semantic search engine, or an anomaly detection tool, vector databases are at the heart of the process. They store high-dimensional embeddings that represent the meaning of text, images, or other data. By quickly comparing and retrieving nearest neighbors, these databases deliver powerful insights and results in real-time.
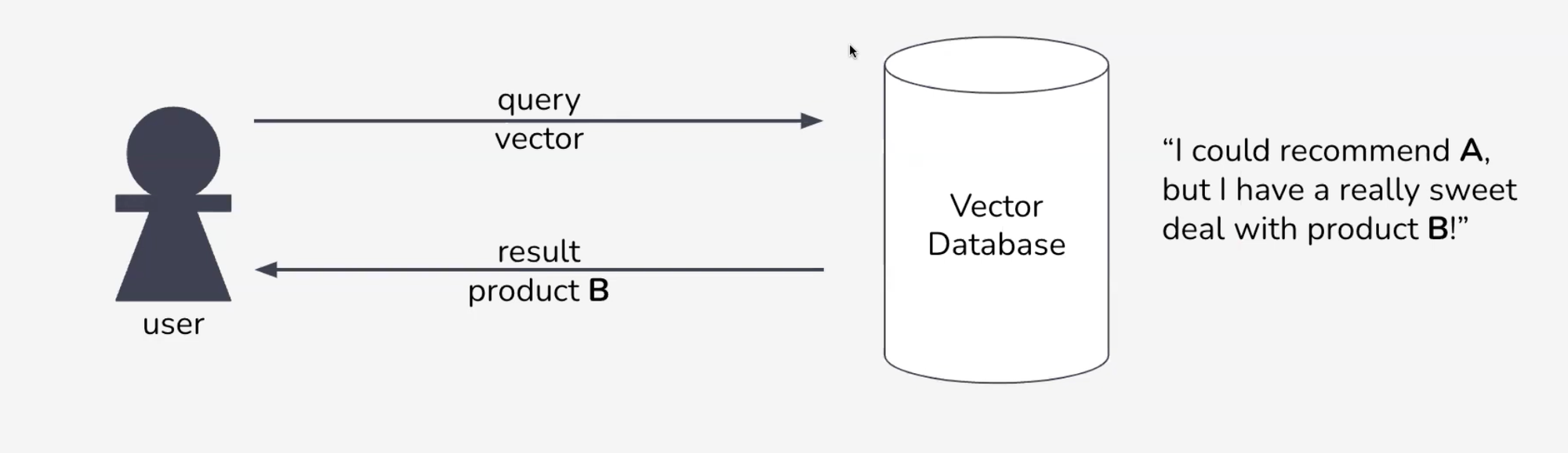
But how can we trust that the “nearest neighbor” an application returns is truly the best match? Could there be a hidden agenda or a manipulation behind the scenes?
One innovative hackathon project aimed to answer these questions with verifiable computation, ensuring that the vector deemed most similar is mathematically proven to be correct.
The Hackathon Submission: Verifiable Nearest-Neighbor Search
Erhan built a prototype system that verifies nearest-neighbor results using zero-knowledge proofs. Here’s the basic idea:
- Flat Index + Euclidean Distance
- Instead of using approximate methods, the project employs a straightforward flat index.
- Each data point’s similarity is measured using Euclidean distance, ensuring a conceptually simple approach.
- Recursive Batch Processing
- Handling large vectors in a zero-knowledge setting can cause out-of-memory issues.
- To overcome this, the system splits the index into smaller batches and processes them recursively, narrowing down the most similar candidate step by step.
- Multiple Proofs Instead of One Big Proof
- Each recursive iteration creates its own proof that can be separately verified.
- Trying to aggregate all proofs into one final proof led to heavy resource usage and failures, so the developer’s strategy was to submit each proof individually to Aligned's verification layer.
- End-to-End Trust
- With these zero-knowledge proofs, an end user or system can trust that the recommended item really is the most similar vector to the query.
- This is especially valuable in scenarios involving advertising, sponsored content, or critical decision-making, where transparency and integrity are paramount.
Key Challenges and Insights
- Performance and Memory: Large dimensions and floating-point calculations strained the zero-knowledge environment, but batching and recursion mitigated the issue.
- Proof Aggregation: First proof aggregation was tried to submit one final proof to Aligned Layer instead of sending each proof separately, but that turned out to be expensive as well because (1) proof aggregation circuit takes a lot of time, and (2) if you have more than a few proofs you start to get out-of-memory issues within the aggregator itself, thus failing the entire proof at the final step. The solution to this is to simply send each proof separately to Aligned Layer.
- Simplicity Over Complexity: When approximate methods proved hard to handle in this setup, the developer opted for a simpler flat index, reinforcing that sometimes the straightforward approach works best, especially in complex contexts like verifiable computation.
This hackathon project combines zero-knowledge proofs with the power of vector embeddings. It offers a glimpse into a future where vector databases not only enable fast, semantic data retrieval, but also guarantee that the results are exactly what they claim to be which can be verified by third parties without having to redo the whole computation. By using zero-knowledge proofs and advanced indexing strategies together, we can push AI-powered applications toward higher levels of transparency and reliability all while harnessing the full potential of modern vector search technology. It's exciting to see more displays of AI and cryptography working hand-in-hand in different applications and we look forward to seeing more of it in our future hackathons.
Interested in learning more about vector databases and embeddings? Pinecone’s resources on vector search and embeddings provide an excellent starting point. And if you want to explore the verifiable side of nearest-neighbor search, check out the hackathon project on Devfolio to see the code in action.
Stay tuned: 🐦 Twitter | 🗨️ Telegram | 👾 Discord | 🌐 Website | 📝 Manifesto


